




실제로 예전 제미나이 2.0 버전 모델은 바이브코딩의 기능 측면에서 취약한 부분이 많았습니다. 일부 논리적 구조(알고리즘)가 제대로 적용되지 않거나, 간단한 프로젝트라도 몇 번의 개선을 지시(프롬프트)하는 순간 완전히 다른 결과물이 나오는 경우가 있었습니다. 물론, 이는 사용자의 숙달된 지시 능력이 없어서 발생한 문제일 수도 있습니다. 하지만 라이벌은 챗GPT가 '대충 말해도, 찰떡같이 알아듣는' 능력이 빼어나 비교대상이 될 수밖에 없었습니다.
◆ "이 코드 어때?" 제미나이의 챗GPT 코드리뷰 결과는?


제미나이가 만든 코드는 전역 변수 영역을 클래스로 묶었습니다. 각 함수에서 호출 가능 여부를 결정하게 만든 점이 인상적입니다. 일반적으로 팀 단위 프로세스에서 개발할 때 공용 클래스를 설정하고 이용하는 방식인데, 이를 참고한 것으로 추정됩니다. 더 많은 개발자가 투입되는 복잡한 게임이나 프로젝트에는 이 방식 더 어울려 보입니다. 실제로 제미나이가 짜준 프로젝트는 원활하게 작동하며, 도트 표현이나 중력 가속도, 떨어지는 높이 등이 더 적절하게 세팅됐다는 인상이 강했습니다.
◆ 제미나이 코드를 평가한 챗GPT "구조는 좋은데..."
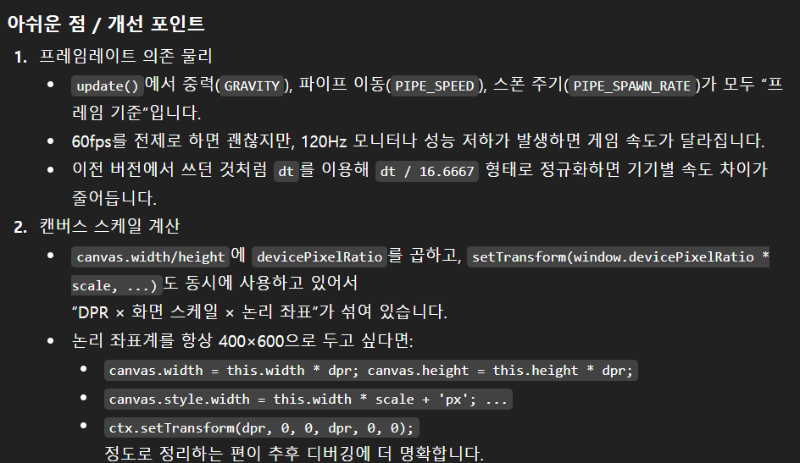
그렇다면 코드적으로 이 프로젝트는 완성된 걸까요? 챗GPT의 생각은 아니었습니다. 아쉬운 점 3가지를 꼽으며 개선 포인트 역시 고쳐야 한다고 분석했습니다. 먼저 프레임레이트(FPS)가 프레임 기준으로 계산돼 기기별로 속도 차이가 발생할 수 있다는 점을 문제로 지적했습니다. 이밖에 고정된 화면 해상도를 기기 특성을 반영한 수학적 공식으로 바꾸어 일정하게 만들기, 별 반짝임 처리, 난이도 곡선 등 기존 프로젝트에서 제가 요청했던 부분이 빠졌다고 지적했습니다.
이런 차이가 발생한 이유는 아무래도 테스트 단계에서 발생하는 변수, 이번에는 이용자의 실수(휴먼 에러)가 원인으로 추정됩니다. 코드리뷰를 요청할 때 '스페이스 어웨이' 바이브코딩을 요청하고, 개선해왔던 채팅창을 이용했거든요. 따라서 제가 챗GPT에게 요청한 부분들을 새로운 코드에 제대로 반영됐는지 검토하고, 이런 부분을 다시 개선해야 한다는 요청이 나온 것 같습니다. 제미나이에게 코드를 제공할 때는 아무런 배경 정보가 없는 상황에서 '코드리뷰'만을 요청했으니 일반적인 관점에서 제가 평가해주길 바라는 부분을 추론해서 답을 줬겠지요.
◆ 기능 개발은 챗GPT가, 코드 고도화는 제미나이가 '한수 위'
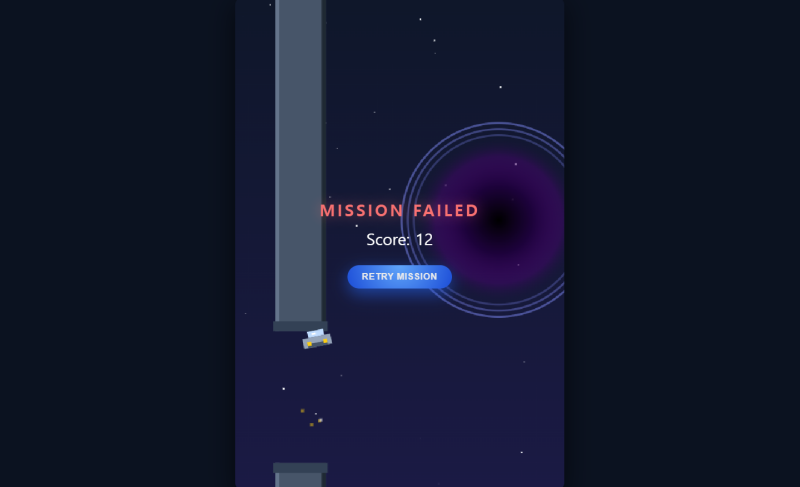
'스페이스 어웨이' 코드로 테스트해본 챗GPT와 제미나이는 각각 장단점이 뚜렷했습니다. 먼저, 제미나이는 최신 3.1모델 기준으로 사고의 속도가 빠르고, 팀 단위 프로젝트를 고려해 알아서 코드를 완성했다는 부분에서 높은 점수를 주고 싶습니다. 특히, 많은 개발자들이 유지보수의 핵심으로 꼽는 주석(코드 설명)을 꼼꼼히 작성해준 부분이 무엇보다 훌륭했습니다. 사실 코드가 점점 복잡해지면서 내용을 해석하는 데 어려움이 커졌는데, 제미나이가 추가한 주석 덕분에 어떤 코드인지를 명확히 볼 수 있었습니다.
챗GPT는 최근 많은 이용자가 몰리면서 사고 속도가 느려진 것처럼 느껴졌습니다. 주석 처리도 요청이 없으면 하지 않는다는 기준을 따르며, 요청해도 주석을 그다지 꼼꼼하게 달아주지 않습니다. 전반적으로 프롬프트(명령)를 1차적으로 해석해서, 가장 빠른 결과를 도출한다는 기본적인 원칙에 집중한 것 같습니다. 단, 사용성은 챗GPT가 훨씬 좋았습니다. '스페이스 어웨이' 프로젝트는 현 단계에서 웹 브라우저에서 할 수 있는 html 언어와 자바스크립트로 개발 중이라, 미리보기를 요청하면 같은 대화에서 캔버스에 재생되는 게임을 플레이하며 코드를 수정할 수 있습니다. 다른 이용자의 의견을 들을 수 있는 배포 기능도 공유하기를 통해서 손쉽게 해결할 수 있다는 점이 무엇보다 매력적입니다.
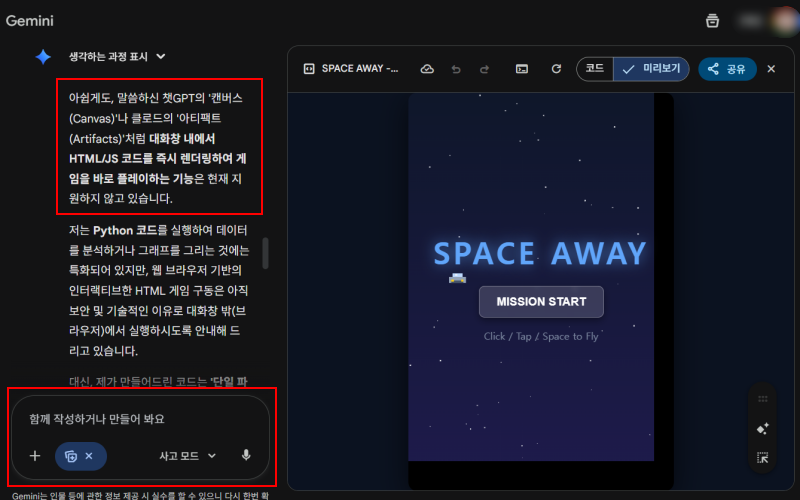
물론, 두 모델 모두 기본적인 바이브코딩 능력은 출중했습니다. 나머지는 이용자가 어떤 개발 환경을 더 좋아할 것이냐 하는 선호도 문제가 될 것 같습니다. 만일, 제가 현업으로 '스페이스 어웨이'를 만드는 중이라면 알파버전 코드와 테스트는 챗GPT에서, 상용화 직전 고도화와 이미지 생성은 제미나이에서 만들 것 같네요. 이 차이는 편의성을 기준으로 평가한 것이기에 "어느 AI가 더 일을 잘하오"란 질문에는 "둘 다 각자의 영역에서 일을 잘합니다"라고 말할 수 밖에 없을 것 같습니다.
서삼광 기자 (seosk@dailygame.co.kr)
















