




'독자 AI 파운데이션 모델' 프로젝트의 성과를 공개하는 1차 발표회가 30일 서울 코엑스 오디토리움에서 개최됐다. 이번 발표회에는 NC AI, 네이버클라우드, 업스테이지, SK텔레콤, LG AI연구원 등 '국가대표 AI 정예팀'으로 선정된 기업들이 참여해 약 4개월간 진행된 성과를 발표했다.

5개 정예팀은 거대언어모델(LLM)의 고도화와 함께, 한국 이용자와 산업현장에 맞춘 다양한 특화 모델을 선보이며 기술적 완성도를 강조했다. 텍스트, 음성, 이미지, 영상 등 한국어 기반의 다양한 입력 데이터를 분석하고, 법률이나 정신건강, 산업현장 점검 등 다양한 분야에 조언을 하는 모델들이 공개됐다.
◆ 네이버클라우드, '옴니 멀티모달' 모델로 차별화… AI 생태계로 삶의 변화 이끈다
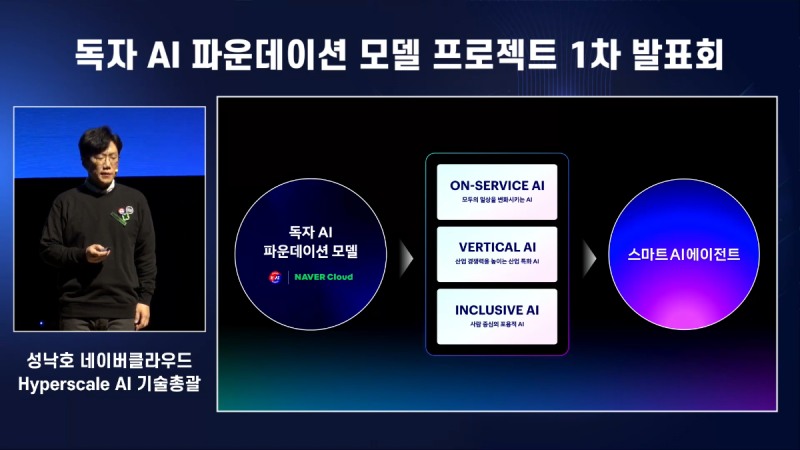
네이버클라우드 성낙호 하이퍼스케일 AI 기술총괄은 옴니 멀티모달을 바탕으로 '하이퍼클로바 X 시드 32B 씽크'와 '하이퍼클로바 X 시드 8B 옴니' 고도화를 추진한다. 올해 프로젝트를 진행하며 가능성 검증을 마쳤고, 오는 2027년까지 모델을 지속 업그레이드한다는 청사진도 제시했다.
구체적인 추진 전략은 ▲온 서비스 AI ▲버티컬 AI ▲포용적 AI 등이다. 온 서비스 AI는 검색 서비스 네이버에 AI 브리핑과 국민비서 등 AI 접근성을 높이는 전략이다. 버티컬 AI는 특정 산업 전문 지식과 경험을 동시에 학습해 맞춤형 지식을 제공하는 데 초점을 맞춘 전략이다. 마지막 포용적 AI는 누구나 AI 혜택을 누릴 수 있게 찾아가는 서비스를 의미한다.
◆ NC AI, 게임·제조·패션 등 산업 특화 브랜드 '뱃키' 공개

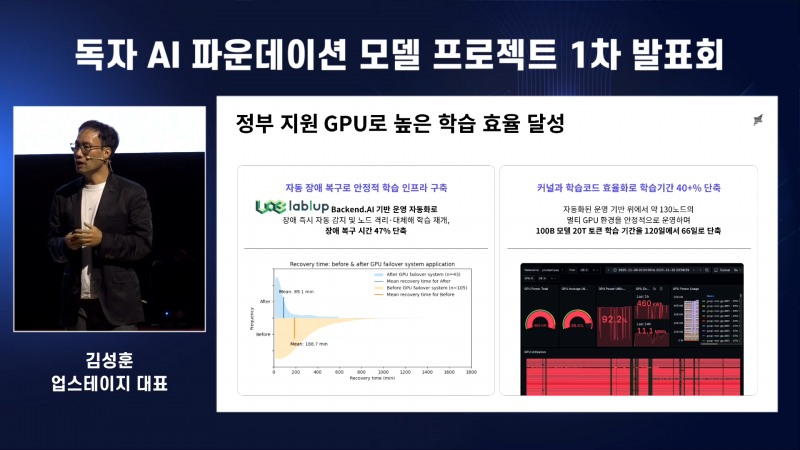
NC AI는 제조에 특화된 거대 컨소시엄을 꾸리고, AI 개발에 필요한 데이터 및 현장 경험을 녹여낼 예정이다. 여기에 ▲전문성과 유연성 ▲보안과 통제 ▲비용 효율성 등을 산업 특화 AI에 필요한 조건으로 설정했다고 밝혔다. 이를 위한 AI 모델 브랜드 뱃키(VAETKI)로 확정했다고 덧붙였다. 뱃키는 'Vertical AI Engine for Transformation of Key Industries'의 약자로, 주요 산업의 혁신을 위한 산업 특화형 AI 엔진이란 뜻을 담았다.
이 대표는 NC AI가 1단계 목표를 초과했다며 자신감을 드러냈다. 발표에 따르면 고품질 한국어 데이터와 산업 데이터를 확보했고, 100B 규모의 LLM 모델 개발도 마무리했다. 또한 28개 이상의 산업 현장에서 프로젝트를 진행해 성과를 냈다는 점을 강조했다. 프로젝트가 마무리되는 2027년까지 목표는 글로벌 수준의 AI 안정성과 신뢰성 표준 인증이다.
◆ 업스테이지, 혁신적 AI 모델 개발 도전
이날 현장에서는 100B급 '솔라 오픈' 모델을 발표했다. 업스테이지가 개발해 온 솔라 모델의 업그레이드 버전으로, 다양한 응용 서비스 및 에이전틱 모델을 선보일 계획이다. 또한, 2026년까지 200B급 LLM으로 규모를 키워 효율성을 높이고, 최종적으로는 300B급 까지 규모를 확장하는 데 집중한다.
이를 통해 제공되는 서비스는 실시간 번역 서비스, 전국민 대상 해커톤, 비영리 기관 무료 제품 제공 등 공공 서비스와 교육을 포괄한다. 김 대표는 서비스 공개의 의미를 새로운 혁신을 위한 시도라고 설명했다.
◆ SK텔레콤, 500B 초거대 모델 'A.X K1'으로 AI의 가능성 넓혀

SK텔레콤은 AI의 국내 활용을 넘어 글로벌 진출을 단계적으로 추진한다. 글로벌 빅테크 기업에서 AI 프로젝트를 주도한 인사들을 중심으로 글로벌 단위 경쟁에 적용할 수 있는 노하우를 발휘하겠다는 점이다. 또한, 이미 글로벌 1200만명의 사용자를 보유한 학술지식 서비스 라이너에 에이닷 서비스를 접목하고, 기존 에이닷 서비스를 통해 누구나 쉽게 AI 서비스를 이용할 수 있도록 대중화를 추진한다.
초거대 모델 개발을 지속적으로 추진한다는 계획도 공개했다. 정 CIC장은 앞으로 모델 규모를 2조(2T, 2트릴리언)까지 확장하고, 영상이나 행동까지 이해하는 AI 모델로 고도화에 나선다. 최종적으로는 글로벌 최고 수준의 AI와 경쟁하며 한국이 AI를 소비하는 나라에서 수출하는 나라가 되는데 기여하겠다는 목표를 밝혔다.
◆ LG AI연구원, 확실한 데이터로 AI 신뢰성 끌어 올린다
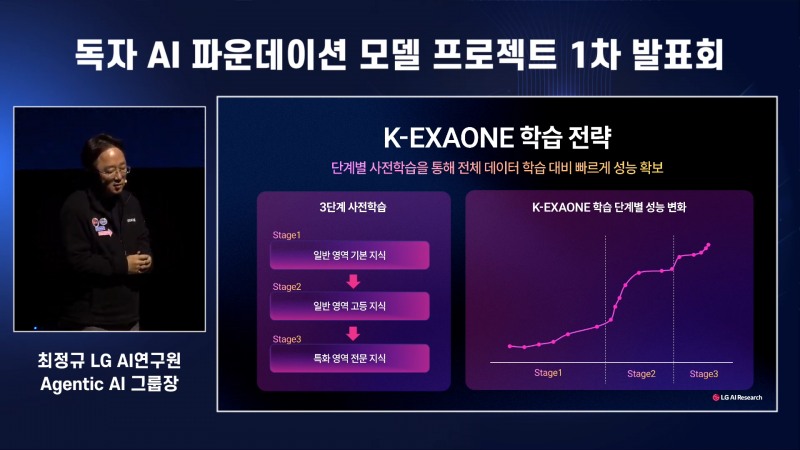
최 그룹장은 'K-엑사원(EXAONE)'이 하이브리드 어텐션 구조로 메모리 요구량과 연산량을 30% 수준으로 줄였다고 설명했다. 최근 AI 개발 및 학습에 과도한 전력과 자원, 메모리가 투자되는 현상을 의식한 것으로 풀이된다. 또한, 단계별 사전학습을 통해 전체 데이터 학습 대비 성능을 빠르게 확보한다는 전략도 소개했다.
데이터의 신뢰도를 높이는 데에도 신경쓴다. 모든 학습 데이터에 대한 데이터 평가 프로세스를 운영해 AI가 잘못되거나 불법 데이터로 학습하는 행위를 방지한다. 이를 위해 자체 AI윤리위원회를 통한 위험분류 체계 수립과 안정성 테스트로 신뢰성을 보장하는 검토 절차를 병행한다.
한편, 과학기술정보통신부는 5개 정예팀의 1차 평가 결과를 오는 2026년 1월15일을 마감 기한으로 공개할 예정이다.
서삼광 기자 (seosk@dailygame.co.kr)


















