크래프톤(대표 김창한)은 AI 모델 브랜드 '라온(Raon)'을 론칭하고, 음성 지원 대규모 언어 모델(LLM), 실시간 음성 대화 모델, 텍스트-음성 변환(TTS) 모델 및 비전 인코더를 글로벌 플랫폼 허깅페이스에 오픈소스로 공개했다고 2일 밝혔다.
Raon은 '즐거움'을 뜻하는 순우리말 '라온'에서 착안한 이름으로, 영문명은 KRAFTON의 일부 철자를 활용해 만들었다. AI 기술을 통해 게임의 본질적인 즐거움을 창출하고자 하는 크래프톤의 철학을 반영했다.
크래프톤은 이번 모델 공개를 통해 데이터 수집부터 모델 학습, 성능 평가까지 파운데이션 모델 개발 전 과정을 자체적으로 수행할 수 있는 기술 역량을 입증했다. 향후 AI 모델 브랜드 'Raon'을 중심으로 글로벌 AI 기술 경쟁력을 더욱 강화해 나갈 계획이다.
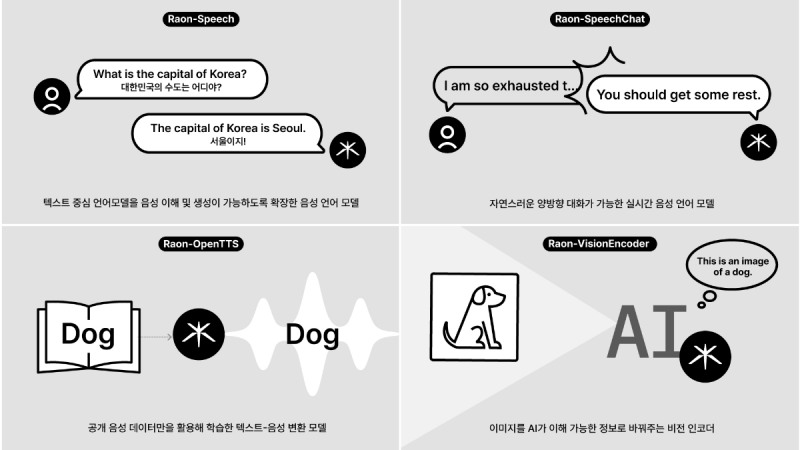
이번에 공개된 모델은 ▲Raon-Speech ▲Raon-SpeechChat ▲Raon-OpenTTS ▲Raon-VisionEncoder 등 음성과 시각 정보를 아우르는 멀티모달 모델로 구성됐다.
(제공=크래프톤).
'Raon-Speech'는 텍스트 중심 언어 모델을 확장해 음성 이해와 생성이 가능한 음성 언어 모델이다. 90억(9B) 파라미터 규모로, 10B 이하급 공개 음성 언어 모델 중 음성 텍스트 변환, 텍스트 음성 변환, 음성 기반 질의응답 등 7개 핵심 태스크 및 40개 벤치마크를 종합 평가한 결과 영어와 한국어 모두 글로벌 1위 성능을 기록했다.
'Raon-SpeechChat'은 사용자와 모델이 대화 중 자유롭게 끼어들 수 있는 실시간 양방향 통신(Full-duplex) 기술을 적용한 음성 언어 모델이다. 국내에서 발표된 최초의 실시간 양방향 음성 모델이다. 'Raon-OpenTTS'는 공개 음성 데이터만으로 학습된 텍스트-음성 변환 모델이다. 기존에 활용이 어려웠던 일부 데이터는 직접 수집 및 정제하여 공개했으며, 전체 학습 데이터도 공개해, 누구나 학습 과정을 재현할 수 있도록 했다.
'Raon-VisionEncoder'는 이미지를 AI가 이해 가능한 정보로 바꿔주는 비전 인코더다. 비전 인코더를 언어 모델과 결합할 경우 시각 정보를 처리할 수 있으며, 공개 데이터만 활용해 사전 학습된 모델을 쓰지 않고 처음부터 자체 학습했다. 일부 시각 인식 태스크에서 구글의 대표 비전 인코더 모델(SigLIP2)를 상회하는 결과를 기록했다. 그 외 태스크에서도 SigLIP2 대비 90% 이상의 성능을 보였다.
크래프톤 이강욱 최고인공지능책임자(CAIO)는 "Raon 모델 시리즈 공개는 AI 기술 역량을 축적해 나가는 과정의 중요한 이정표"라며 "대규모 학습 데이터와 핵심 모델을 오픈소스로 공유해 연구자와 개발자들이 자유롭게 활용할 수 있도록 하고, 멀티모달 기술 발전과 국내 AI 생태계의 성장에 기여하기를 기대한다"라고 밝혔다.